- Trigger side effects and workflows in your application
- Maintain a sync of API data in your database
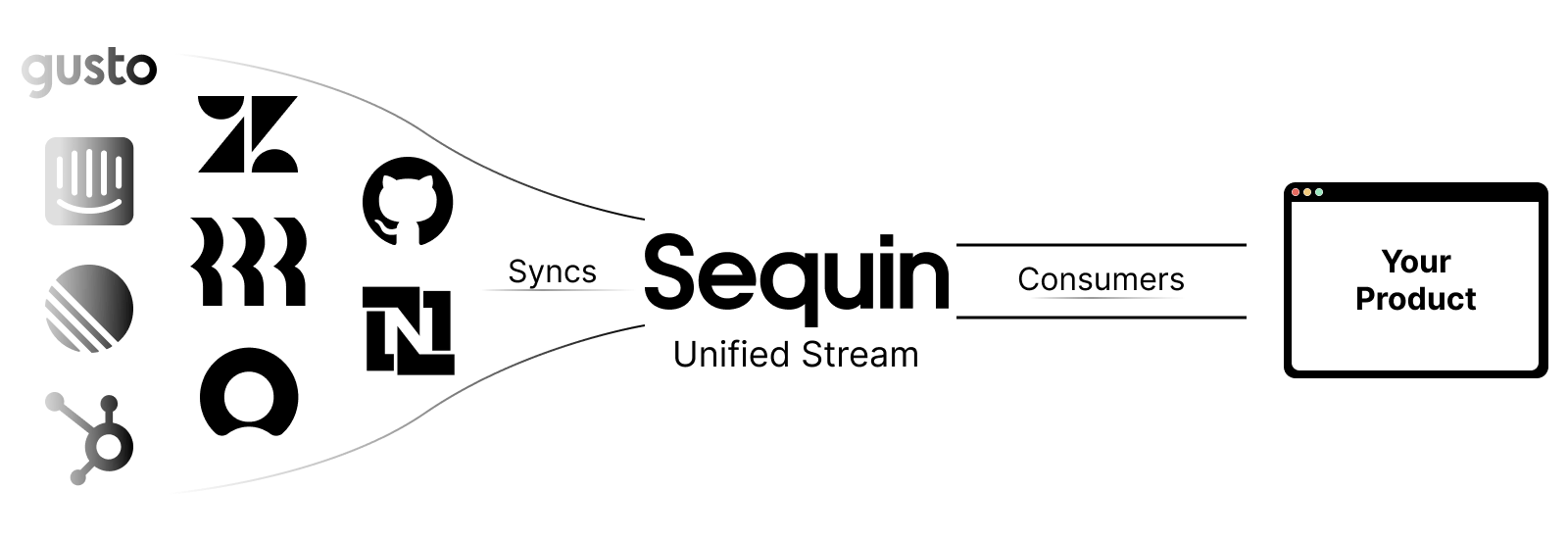
Who’s it for?
Sequin is a great fit if you are building complex or high-throughput API integrations. Sequin is also a great fit if you’re just getting started with your integrations and want to save as much time as possible.Which providers are supported?
Sequin currently supports:- Adyen
- Asana
- Ashby
- Airtable
- Auth0
- AWS Lambda
- BambooHR
- Braintree
- Braze
- Brex
- Clerk
- Deel
- Figma
- Front
- GitHub
- Gong
- Google Sheets
- Greenhouse
- Gusto
- HubSpot
- Intercom
- Jira
- Klaviyo
- Lever
- Linear
- Marketo
- Monday
- NetSuite
- Notion
- PagerDuty
- Quickbooks
- Rippling
- Sage
- Salesforce
- SAP
- SendGrid
- ServiceNow
- Shopify
- Slack
- Square
- Stripe
- Twilio
- Typeform
- Workday
- Xero
- Zendesk
- Zenefits